
So Sam Bhagwat recently dropped a 150-page book on building AI agents, and it’s all around the internet. He sent me a copy too and honestly? It’s actually kinda good (well until 2025 ends at least)
Whenever someone asks me how do they “Learn AI”, my standard answer is always FAFO (F around and Find out)
And it’s still very relevant!
By the time someone launches a course or writes a book (which usually suck btw) - and by the time you finish it, it’s already outdated. (this one is slowly going outdated-ish too, there are updates to some models)
Unlike the usual AI hype garbage, this is actually kinda cool and seems like it’s written by someone that actually y’know BUILDS PRODUCTION STUFF!?
So yeah, I spent today’s Metro ride reading through this book and boiled it down to stuff you can takeaway without reading the entire thing - of course, it wouldn’t be as detailed but you’d get a great idea :)

An extremely handsome looking guy holding the book
The Elephant in The Room
Okay, this book is insane marketing for Mastra. And I mean that as high praise.
Sam and his co-founders are building an open-source JavaScript framework for AI agents and are a YC W25 startup.
The book is “free” if you’re in the space. The code examples are generic enough to apply anywhere. But every principle, every pattern, every “here’s how the pros do it” just so happens to align perfectly with what Mastra provides, but hey it’s still good quality haha
Part I: Prompting
The Foundation: What Even Are LLMs?
Quick history lesson because it’s really cool:
“AI” in general has been along for a long time. From Chess engines, Game NPCs, Rule based Chatbots like ELIZA (I recreated this one btw, it’s really fun)
- 2017: Google publishes “Attention is All You Need” - the amazing transformer architecture paper (seriously recommend reading it if you haven’t here)
- November 2022: ChatGPT drops and goes viral overnight
- Now: We’ve got OpenAI, Anthropic (Claude), Google (Gemini), Meta (Llama), and a bunch of others making increasingly capable models
LLMs predict the next token (word/punctuation) based on what came before. To oversimplify, That’s… about it
Choosing Your Model: The First Real Decision
Before you write a single line of code, you need to pick a model. Here’s the book’s hierarchy of considerations:
Start with Hosted Models (Seriously)
Even if you think you’ll need open-source later, prototype with cloud APIs first (OpenAI, Anthropic, Google). Why? Because debugging infrastructure issues instead of iterating on your actual product is a cute and special kind of hell.
Try to use a model routing library (shout out to Vercel, Josh and AI SDK) so you can swap providers without rewriting everything.
The Size-Speed-Cost Triangle
Every major provider has:
- Big models: Expensive, slow, accurate (GPT-4, Claude Opus)
- Small models: Fast, cheap, less accurate (GPT-4o mini, Claude Haiku)
Start expensive while prototyping. Once it works, optimize cost. Makes sense—you can’t optimize something that doesn’t work.
Context Windows Matter More Than You Think
Context window = how much text the model can “remember” at once.
- Gemini Flash 1.5 Pro: 2 million tokens (~4,000 pages)
- Most others: 128k-200k tokens
This matters because sometimes the easiest solution is just shoving your entire codebase into the context window and letting the model figure it out. Brute force? Sure. Effective? Bet.
Reasoning Models are REALLY cool
Models like o1 and o4 don’t just generate, they think first, just like you (probably) do. They break down complex problems, show their work, and return higher-quality responses. But, They’re slower, MUCH slower and work best as “report generators”, give them tons of context upfront, let them cook.
Chain-of-thought prompting lets these models show their work, step by step. Even better, newer methods like ‘chain of draft’ help them stay focused.
Writing Prompts That Actually Work
Here’s where most people screw up. They treat LLMs like search engines. Wrong move.
The Three-Shot Approach
- Zero-shot: YOLO it. Ask and hope. (Usually disappointing)
- Single-shot: Give one example with input + output. (Better)
- Few-shot: Multiple examples for precise control. (Best)
More examples = more guidance, but also more tokens (money). Find the balance.
The “Seed Crystal” Hack
Not sure how to prompt something? Ask the model to write the prompt for you:
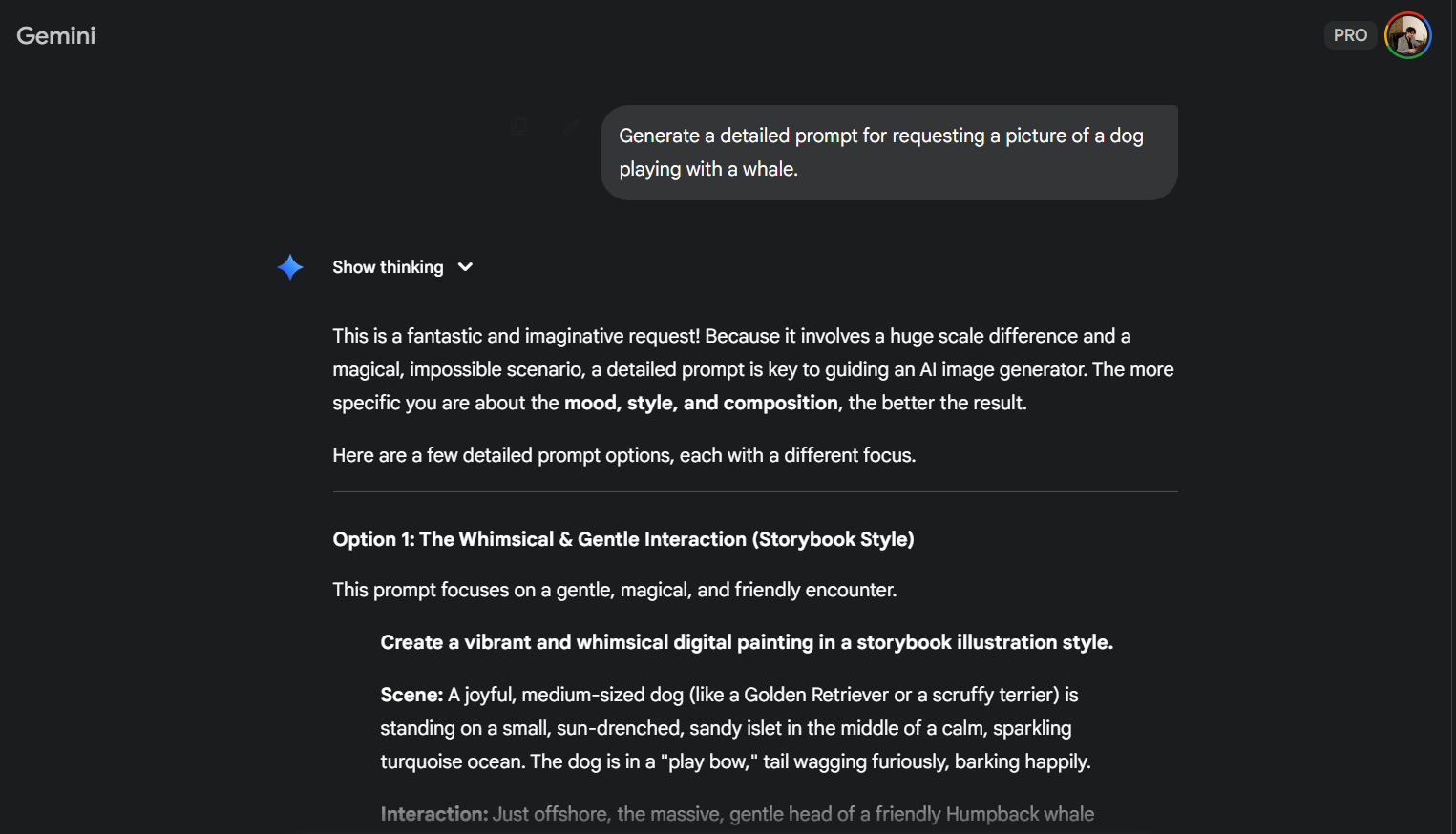
Then iterate on what it gives you. Claude is best at writing prompts for Claude, GPT-4o for GPT-4o, etc.
System Prompts 101
System prompts define your model’s personality before the user interacts with it. It won’t improve accuracy much, but it’ll make your agent sound right.
Formatting Tricks That Seem Dumb But Work
- CAPITALIZATION adds weight to words
- XML-like structure helps models follow instructions precisely
- Claude & GPT-4 respond better to structured prompts with clear sections
Example from the book (a production code-gen prompt):
<task>
Generate a functional React component that...
</task>
<context>
The app uses TypeScript and Tailwind...
</context>
<constraints>
- Must be under 100 lines
- No external dependencies beyond React
- Follow accessibility best practices
</constraints>
and If you think your prompts are detailed, go read some production prompts. You’d pass out ;)
Part II: Building an Agent and making AI “Autonomous”
What Makes Something an “Agent”?
I’m taking a principles of AI class so I’ll break it down, In theory, an agent is something (or someone) that can do actions on your behalf with a large degree of accuracy
- Your “friend” can be an agent that sends you the cool moments you missed out when you didn’t come to class
- Your Dog can be an agent to fetch you newspapers in the morning (if you get newspaper these days anyways)
For AI, agentic jobs could be a lot of stuff but involve things like surfing the web, reading through documents, finding a piece of information, etc depending on what tools you give them
Another way to think can be:
Direct LLM calls = contractors. They do one job and leave.
Agents = employees. They maintain context, have specific roles, use tools, and accomplish complex multi-step tasks.
The Agent Autonomy Spectrum
Low autonomy: Binary choices in decision trees
Medium autonomy: Memory, tool calling, retry logic
High autonomy: Planning, subtask division, self-managed task queues
Most production agents right now fall under Low-to-medium. The high-autonomy stuff is still mostly research/demos (thank god for that 💀)
Your First Agent: The Building Blocks
At minimum, an agent needs:
- A name (identifier)
- A model (the brain)
- Instructions (the job description)
- Tools (the abilities)
// Generic agent structure (framework-agnostic pattern)
const supportAgent = {
name: 'customer-support',
model: {
provider: 'ANTHROPIC',
name: 'claude-sonnet-4-20250514'
},
instructions: `You are a helpful customer support agent.
Be friendly, concise, and always try to solve the user's problem.
Use tools when you need specific information.`,
tools: [getOrderStatus, processRefund, escalateToHuman],
memory: {
lastMessages: 10,
semanticRecall: true
}
};That’s the pattern. Name, model, instructions, tools. Every agent framework follows this blueprint.
Model Routing: Don’t Lock Yourself In
Want to test different models without rewriting code? Use a routing abstraction:
// Generic model routing
async function generateWithModel(provider, modelName, prompt) {
const config = {
openai: openaiConfig,
anthropic: anthropicConfig,
google: googleConfig
};
const client = config[provider];
return client.generate({ model: modelName, prompt });
}
// Now you can easily swap:
const result = await generateWithModel('openai', 'gpt-4', prompt);
// Later: await generateWithModel('anthropic', 'claude-sonnet-4', prompt);Why this matters: You’ll experiment a lot. Make it easy to switch. You don’t even need to do this, there are multiple cool libraries to use in prod though that does this way better ;)
Structured Output: Making LLMs Return JSON
When building apps, you want data you can work with and JSON formatting is cool for that
// Pattern for structured output
async function extractJobs(resumeText) {
const response = await model.generate({
prompt: `Extract job history from this resume: ${resumeText}`,
format: {
type: 'json',
schema: {
jobs: [{
title: 'string',
company: 'string',
startDate: 'string',
endDate: 'string'
}]
}
}
});
return JSON.parse(response);
}Something like this is perfect for:
- Parsing resumes into job lists
- Extracting symptoms from medical records
- Converting messy text into clean database entries
Tool Calling and Agents
Tools are functions agents can invoke, fetching weather data, querying databases, processing calculations and more.
Best practices:
- Provide detailed descriptions in both the tool definition AND system prompt
- Use specific input/output schemas
- Use semantic naming (multiplyNumbers not doStuff)
- Describe both what it does and when to call it
When you’re creating an AI application, another important thing you should do is think carefully about your tool design, prompt it REALLY well.
Agent Memory: Not All Context Is Created Equal
LLMs have zero memory between calls. If you want your agent to remember past conversations, you need to handle it.
Working Memory
Working memory stores relevant, persistent, long-term characteristics of users. Ask ChatGPT what it knows about you and it’ll tell you (Sam’s hilariously gets mistaken for a five-year-old girl who loves squishmallows because his kids use his devices).
Hierarchical Memory
Hierarchical memory means using recent messages along with relevant long-term memories.
Think about a real conversation. If you ask me what I did last weekend, I:
- Search my memory for relevant events (last weekend)
- Consider our recent conversation context
- Combine both to formulate a response
Agents should work the same way:
memory: {
lastMessages: 10, // Recent conversation sliding window
semanticRecall: {
enabled: true, // RAG-based search through past convos
topK: 5, // Number of relevant past messages
messageRange: 2 // Include 2 messages before/after matches
}
}This prevents context window overflow while keeping the most relevant information.
Memory Processors: Advanced Context Control
Sometimes you need to prune context deliberately to make sure the outputs are better and you’re not broke from Claude inference.
TokenLimiter: Removes oldest messages until you’re under the limit (prevents overflow errors) ToolCallFilter: Strips out verbose tool interactions from context (saves tokens, prevents staleness)
Dynamic Agents: Runtime Configuration
Static agents are predictable but Dynamic agents are powerful.
A dynamic agent’s properties like instructions, model, and available tools can be determined at runtime:
// Dynamic agent pattern
const dynamicSupportAgent = {
name: 'dynamic-support',
getInstructions: ({ user }) => {
if (user.tier === 'enterprise') {
return 'Provide white-glove support with technical depth...';
}
return 'Be helpful but guide users to self-service docs...';
},
getTools: ({ user }) => {
const basicTools = [searchDocs, createTicket];
if (user.tier === 'enterprise') {
return [...basicTools, escalateToEngineer, accessPrivateDocs];
}
return basicTools;
}
};
// Each interaction gets customized agent configuration
const agent = await createAgent(dynamicSupportAgent, { user: currentUser });but yeah, these can and will be more sensitive so it’s a lot of trial and error to get these just right, you need a lot of evals for this
what are evals, glad you asked… coming up
Agent Middleware: The Security Layer
Middleware is the typical place to put any agent authorization, because it’s in the perimeter around the agent rather than within the agent’s inner loop.
Guardrails: Input/Output Sanitization
Protect against:
- Prompt injection attacks (“IGNORE PREVIOUS INSTRUCTIONS AND…“)
- PII requests
- Off-topic chats that run up your LLM bills
Models are getting better at this. The memorable prompt injections are mostly from 2022-2023.
but yeah I still managed to get Poke for $0.01 through these so you still need good guardrails LOL
Authentication & Authorization
Two layers to consider:
- Which resources should the agent access?
- Which users can access the agent?
Because agents are more powerful than pre-LLM data access patterns, you may need to spend more time ensuring they are permissioned accurately. As I said, good evals
Part III: Tools & MCP – The Agent Ecosystem
Popular Third-Party Tools
Agents are only as powerful as the tools you give them.
Web Scraping & Browser Use
Core use case for agents. Options:
Cloud APIs: Exa, Browserbase, Tavily (paid, reliable)
Open-source: Microsoft Playwright (pre-LLM era, solid)
Agentic: Stagehand (JS), Browser Use (Python, MCP servers available)
Challenges:
- Anti-bot detection (fingerprinting, WAFs, CAPTCHAs)
- Fragile setups (breaks when sites change layout)
These challenges are solvable, just budget time for munging and glue work!
Third-Party Integrations
Most agents need:
- Core integrations (email, calendar, documents)
- Domain-specific integrations (Salesforce for sales, Rippling for HR, GitHub for code)
Options (not limited to though):
- Developer-friendly: Composio, Pipedream, Apify (100s/month)
- Enterprise: Various specialized solutions ($1000s/month)
Model Context Protocol (MCP) The AI USB-C
In November 2024, Anthropic proposed MCP to solve a real problem: every AI provider and tool author had their own way of defining and calling tools.

How MCP Works
Two primitives:
Servers: Wrap sets of tools, can be written in any language, communicate over HTTP
Clients: Models/agents that query servers for tools, then request execution
It’s basically a standard for remote code execution, like OpenAPI or RPC.
The MCP Ecosystem Explosion
After initial skepticism, MCP hit critical mass in March 2025 when OpenAI and Google announced support:
- Vendors (Stripe) shipped MCP servers for their APIs
- Developers published servers for browser use, etc.
- Registries (Smithery, PulseMCP, mcp.run) catalogued the ecosystem
- Frameworks shipped abstractions so devs don’t reimplement specs
When to Use MCP
If your roadmap has a lot of basic integrations (calendar, chat, email, web), it’s worth building an MCP client. Conversely, if you’re building a tool you want other agents to use, consider shipping an MCP server.
Building with MCP (Generic Pattern)
Server side:
// Generic MCP server pattern
const mcpServer = {
name: 'weather-service',
tools: {
getWeather: {
description: 'Get current weather for a city',
parameters: { city: 'string' },
execute: async ({ city }) => {
// Weather API call
return { temp: 72, condition: 'sunny' };
}
}
}
};
// Server exposes tools over HTTP
startMCPServer(mcpServer, { port: 3000 });Client side:
// Generic MCP client pattern
const client = new MCPClient({
serverUrl: 'http://localhost:3000'
});
const tools = await client.getTools();
const agent = {
name: 'weather-agent',
tools: tools, // Dynamically loaded from server
// ...
};yes, it is that simple LOL
MCP Challenges
The ecosystem is still working to resolve a few challenges: First, discovery. There’s no centralized way to find MCP tools. Second, quality. There’s no equivalent of NPM’s package scoring. Third, configuration. Each provider has its own schema and APIs.
You could easily spend a weekend debugging subtle differences between how Cursor and Windsurf implemented their MCP clients. There’s alpha in playing around with MCP, but you probably don’t want to roll your own, at least not right now when everything’s chaos.
Part IV: Graph-Based Workflows – When Agents Need Structure
Why Workflows?
At every step, agents have flexibility to call any tool. Sometimes, this is too much freedom. Graph-based workflows have emerged as a useful technique when agents don’t deliver predictable enough output.
Think about it: Sometimes you need to define the decision tree and have an agent make a few binary decisions instead of one big decision.
The Building Blocks
Branching: Parallel Execution
Use case: You have a long medical record and need to check for 12 different symptoms. One LLM call checking for 12 symptoms? That’s a lot. Better: 12 parallel LLM calls, each checking for one symptom.
// Generic workflow pattern
workflow
.step('analyzeForDrowsiness', checkDrowsiness)
.step('analyzeForNausea', checkNausea)
.step('analyzeForFever', checkFever);
// ... 9 more parallel checks, all run simultaneouslyChaining: Sequential Execution
Sometimes you’ll want to fetch data from a remote source before feeding it into an LLM, or feed the results of one LLM call into another.
workflow
.step('fetchData', getData)
.then('processData', processData)
.then('summarize', summarizeLLM);Each step waits for the previous, has access to previous results via context.
Merging: Combining Results
After branching paths diverge to handle different aspects of a task, they often need to converge again to combine their results.
workflow
.step('analyzeText', textAnalysis)
.step('analyzeImage', imageAnalysis)
.merge('combineAnalyses', combineResults);Conditions: Branching Logic
Sometimes your workflow needs to make decisions based on intermediate results.
workflow
.step('fetchData', getData)
.step('processData', processData, {
condition: (ctx) => ctx.fetchData.status === 'success'
});Best Practices
It’s helpful to compose steps so input/output at each step is meaningful, since you’ll see it in tracing. Another is to decompose steps so the LLM only does one thing at a time. This usually means no more than one LLM call per step.
Suspend and Resume: Human-in-the-Loop
Sometimes workflows need to pause execution while waiting for a third-party (like a human) to provide input.
Because responses can take arbitrarily long, you don’t want a running process. Instead: persist state, provide a resume function.
// Generic suspend/resume pattern
const workflow = createWorkflow({
name: 'approval-workflow'
})
.step('generateReport', generateReport)
.step('awaitApproval', async (ctx) => {
ctx.suspend({ reason: 'Awaiting human approval' });
})
.step('publishReport', publishReport);
// Later, when approval comes in:
await workflow.resume(workflowId, { approved: true });This is crucial for production systems where decisions require human judgment.
Streaming Updates: Making Workflows Feel Fast
One of the keys to making LLM applications feel fast is showing users what’s happening while the model is working.
For planning a trip, OpenAI’s o1 just shows a spinning “reasoning” box for 3 minutes. Deep Research immediately asked for details, then streams updates as it found restaurants. Much better UX.
The Streaming Challenge
When building LLM agents, you’re usually streaming in the middle of a function that expects a certain return type. Sometimes you have to wait for the whole LLM output before the function can return a result.
Solution: Escape hatches. Simon at Assistant UI writes every token directly to the database as it streams, using ElectricSQL to sync instantly to the frontend.
What to Stream
- LLM output tokens (showing generation in real-time)
- Workflow steps (agent is searching, planning, summarizing)
- Custom progress updates
Streaming isn’t just nice-to-have at this point, it’s critical for SP+OTA (State of the Art) UX. Users want to see progress, not just a blank screen and our attention spans are already cooked.
Observability and Tracing: Because Your Agent Will Go Off the Rails
LLMs are non-deterministic. They will hallucinate, make mistakes, and behave unpredictably. The question isn’t if your agent will fail—it’s when and how badly.
Tracing: Your Lifeline
OpenTelemetry (OTel) has become the standard. You want to see every step of every workflow: inputs, outputs, latency, errors. It’s like having a debugger for distributed AI systems.
A typical trace view shows you the execution tree. You can drill into any step and see exactly what the model received and what it returned. This is invaluable for debugging.
Evals in Production ;)
Side-by-side comparisons of expected vs. actual responses, scores over time, filtering by tags. It’s how you catch regressions before your users do.
instrument everything, trust nothing. Your future self will thank you.
Part V: RAG – The Pattern Everyone Loves to Hate
Retrieval-Augmented Generation is the duct tape of AI engineering. Your documents are too big for the context window? Chunk ‘em, embed ‘em, retrieve ‘em, synthesize ‘em.
The pipeline:
- Chunking: Break documents into bite-sized pieces
- Embedding: Turn chunks into vectors representing meaning
- Indexing: Store vectors in a database optimized for similarity search
- Querying: Find most similar chunks (cosine similarity)
- Reranking: Post-process with a more expensive model
- Synthesis: Feed results to LLM with user query
while this sounds complex, the vector DB space is commoditized. Unless you’re doing something extremely specialized, just use pgvector if you’re on Postgres, Pinecone if you’re starting fresh, or your cloud provider’s managed service.
I’m personally doing the “specialized” bit personally on SecondYou building context and support for local LLMs but yeah, RAG from scratch a mess if there ever is one.
Setting Up Your Pipeline: The Nuts and Bolts
Chunking Strategies
Balance context preservation with retrieval granularity. Options: recursive splitting, character-based, token-aware, format-specific (Markdown, HTML, JSON).
Embedding
Use OpenAI’s text-embedding-3-small or similar. The vectors are 1536-dimensional arrays representing semantic meaning.
Querying & Reranking
Under the hood: matrix multiplication to find closest point in 1536-dimensional space. Reranking is more computationally intense, so only run it on top results.
Full Pipeline Example
// Generic RAG pipeline
const chunks = await splitDocument(largeDocument);
const embeddings = await embedChunks(chunks);
await vectorStore.upsert(embeddings);
const queryEmbedding = await embedQuery(userQuery);
const results = await vectorStore.query(queryEmbedding, { topK: 5 });
const context = results.map(r => r.text).join('\n\n');
const answer = await model.generate({
prompt: `Context: ${context}\n\nQuestion: ${userQuery}`
});Alternatives to RAG
Agentic RAG
Instead of searching through documents, give your agent a set of tools to help it reason about a domain. A financial advisor agent with market data APIs can be more precise than one searching through PDFs.
Reasoning-Augmented Generation (ReAG)
ReAG focuses on using models to enrich text chunks. Think about what you would do with 10x your LLM budget to improve RAG quality—then go do it.
Full Context Loading
With newer models supporting larger context windows (The Newest Gemini Flash model has 1M+ tokens), sometimes the simplest approach is just loading all relevant content directly into the context.
But honestly, we’re engineers. And engineers can over-engineer things. With RAG, you should fight that tendency. Start simple, check quality, get complex.
- Throw your entire corpus into Gemini’s context window
- Write functions to access your dataset, bundle in MCP server
- If neither works well enough, then build a RAG pipeline
Part VI: Multi-Agent Systems
Think about a multi-agent system like a specialized team at a company. Different AI agents work together, each with their own specialized role, to accomplish complex tasks.
Real example: Replit’s code agent:
- Planning/architecture agent
- Code manager agent
- Code writer agent
- Execution agent
Each has different memories, system prompts, and tools.
designing multi-agent systems involves a lot of organizational design skills. You group related tasks into job descriptions. You think about network dynamics: do three specialized agents gossip until consensus, or report to a manager?
Agent Supervisor Pattern
Agent supervisors are specialized agents that coordinate and manage other agents.
// Generic supervisor pattern
const copywriter = {
name: 'copywriter',
tools: [researchTopic, checkSEO]
};
const editor = {
name: 'editor',
tools: [grammarCheck, styleGuide]
};
const publisher = {
name: 'publisher',
tools: [copywriter, editor, approvalWorkflow],
instructions: 'Coordinate content creation and manage the team'
};Publisher supervises copywriter and editor, making decisions about workflow.
Control Flow: Planning Before Execution
Just as a PM wouldn’t start coding without a plan, agents should establish an approach before diving into execution. We recommend engaging with your agents on architectural details first—adding checkpoints for human feedback in their workflows.
Workflows as Tools
Let’s say you want your agent(s) to accomplish 3 separate tasks. You can’t do this easily in a single LLM call. But you can turn each task into individual workflows. There’s more certainty because you can stipulate a workflow’s order of steps and provide more structure.
A2A vs. MCP
While MCP connects agents to tools, A2A (Agent-to-Agent) is Google’s protocol for connecting agents to each other. It’s younger, less adopted, but solves a different problem: how do untrusted agents communicate?
A2A uses a JSON metadata file that describes capabilities, endpoints, and auth requirements. Tasks flow through a queueing system with states (submitted, working, input-required, completed, failed).
The key difference: MCP is for tool integration, A2A is for agent coordination. MCP is winning, but A2A might carve out a niche in cross-organizational communication.
Part VII: Evals – How to Tell If Your Agent Is Actually Good
The Part you were (hopefully) waiting for
Traditional software tests are pass/fail. AI evals return scores between 0 and 1. It’s like performance testing: there’s variance, but over time you see correlation with quality.
It’s like IQ tests somewhat - a somewhat alright way to measure intelligence but you still gotta chime in.
Textual evals are like a pedantic TA with a rubric:
- Hallucination: Are there facts not in the context?
- Faithfulness: Does it accurately represent provided context?
- Context precision: Are chunks grouped logically?
- Answer relevancy: Does it actually answer the question?
Other eval types include classification evals, tool usage evals, prompt engineering evals, and A/B testing. The leaders (Perplexity, Replit) rely more on live A/B testing than formal evals because they have enough traffic to detect quality degradation quickly.
Human data review is still crucial. Many correctness aspects can’t be captured by rigid assertions, but human eyes catch nuances. The best teams regularly review production traces.
Part VIII: Development & Deployment – Everything Burns
Agent development has two parts: frontend and backend.
Frontend is chat interfaces, streaming, tool call displays. Frameworks like Assistant UI, Copilot Kit, and Vercel AI SDK UI speed this up.
Backend is where the complexity lives. You need:
- Agent chat interface for testing
- Workflow visualizer for debugging execution flow
- Tool playground for verifying inputs/outputs
- Tracing and evals integration
A good local dev environment gives you all this. You can see every tool call, every decision, every failure in real-time.
Deployment
May 2025: We’re still in the early days of agent deployment. Most teams are Dockerizing web servers and deploying to platforms that can scale them.
The challenges are unique:
- Agent workloads are long-running, like durable execution engines
- But they’re tied to user requests, so they need HTTP interfaces
- Serverless timeouts kill long processes
- Bundle sizes are huge
Teams using container services like AWS EC2 or Digital Ocean are sleeping better than those trying to force agents into Lambda functions. The managed platform space is emerging, but we’re still early.
Part IX: Everything Else – The Kitchen Sink
Multimodal: The Next Frontier
just as the internet added images in the ’90s and video in the 2000s, AI is following the same pattern. Text came first, images are having their moment (Ghibli-core, March 2025), voice and video are getting way better.
Image generation has crossed into the “consumer-grade” phase.
Voice is trickier. Realtime voice (speech-to-speech) is computationally expensive and struggles with turn-taking. Most production systems use STT → LLM → TTS pipelines.
Video is still in the “machine learning” phase, not the “AI engineering” phase. Consumer models can’t consistently represent characters across scenes. It’s coming, but not fully here yet.
Code Generation
Code generation tools (bolt.new, Lovable, Replit) are the hottest thing-ish. They work by giving agents:
- Feedback loops: Write code, run it, analyze errors, iterate
- Sandboxing: Run untrusted code safely (seriously, never execute LLM-generated code on your host machine)
- Analysis tools: Linters, type checkers provide ground truth feedback
The safety considerations are massive. Sandboxing is non-negotiable. But the productivity gains are real but you still see purple gradients on every new portfolio website so who’s to judge.
What’s gonna come up
AI is very unpredictable and the top labs are usually very quiet and secretive until just the model drop but here are some predictions that were in the book
- Reasoning models will keep getting better. What do agents built specifically for them look like? We’re still figuring that out.
- Agent learning will progress. Right now, the feedback loop is human-driven. Teams are working on supervised fine-tuning from agent traces.
- Synthetic evals will explode. Writing evals is manual and tedious. Products that generate evals from trace data will become essential.
- Security will become critical. The GitHub MCP server vulnerability that leaked private repos is just the beginning.
- The eternal September of AI continues. Every month brings new developers who’ve never written a prompt. The field moves so fast that we’re all perpetual beginners. Humility is required.
The Distilled Version: What Actually Matters
Here’s the TL;DR for when you’re building at 2 AM and need to remember what Sam would do:
1. Start with hosted models. Don’t be a hero. Use OpenAI, Anthropic, or Google until you have product-market fit. Then worry about open-source.
2. Prompt engineering is real engineering (Okay, somewhat). Few-shot examples, clear formatting, and system prompts aren’t tricks, they’re the API. Treat them with respect.
3. Tool design is the most important thing. Before you write a line of code, write down every tool your agent needs. Think like an analyst, not a programmer.
4. Memory makes agents useful. Working memory + hierarchical memory = agents that remember you. Without it, you’re just building slightly smarter search.
5. Workflows beat free-form agents for predictability. When you need reliability, trade flexibility for structure. Graph-based workflows give you observability and control.
6. RAG is a last resort. Before you build a vector database pipeline, try throwing everything in the context window. Then try MCP tools. RAG is powerful but overused.
7. Evals are non-negotiable. If you can’t measure quality, you can’t maintain it. Build evals early, run them often, review production traces religiously.
8. Deployment is still hard. We’re in the Heroku era of agents. Use managed platforms with autoscaling. Don’t force agents into serverless until the platforms catch up.
9. Security will bite you. Agents are powerful and access more data. Permission them correctly from day one.
10. Stay humble. The field moves so fast that expertise has a half-life of months. We’re all perpetual beginners. Build with that in mind.
Final Thoughts: Why This Book Slaps (And Why Mastra Wins)
This is the sort of book I wish existed a year ago when I first started playing with AI. There is quite a bit of substance to it and it’s very concise for 150 pages.
What makes it special is the tone. It’s not an academic treatise or a vendor pitch. It’s written by someone who recognizes the same patterns playing out in AI. The frameworks will come and go, but the principles remain.
The e-book is free at mastra.ai/book and you should read it if you have the time or spam his dms asking for a physical copy. it feels almost criminal given the value density. But that’s the open-source playbook: give away the knowledge and then sell the shovels.
If you’re building AI agents or assistants, read this book. Not because you’ll agree with everything - I disagreed with a lot of stuff personally too, but this is an industry that runs on opinions and gives you a mental model for reasoning about this new paradigm. In a field where the most influential people are shouting about AGI and the end of programming, Sam explained how to actually build something useful today, which I have respect for.
Happy building. And may your agents always call the right tools on the first try.