
When a cryptic billboard led to the most addictive coding challenge of 2025
Optimization problems are quite literally digital crack cocaine. Once you get a taste of turning 1,200 rejections into 1,150, then 1,000, then watching that number drop digit by agonizing digit - you’re hooked (even when each run takes ~40 minutes). And when Listen Labs accidentally created the most engaging technical challenge of 2025 with their Berghain Challenge, I found myself tumbling down a rabbit hole that would consume days of my life and introduce me to some of the most brilliant problem-solvers on the internet.

This is the story of how a startup’s growth hack became a 30,000-person distributed computing experiment, how I went from a complete algorithmic newbie to ranking #16 in a field of the world’s most obsessive engineers, and why sometimes the journey matters more than the destination.
The Billboard That Broke The Internet
It started, as all good internet mysteries do, with something cryptic.
Imagine you’re driving through San Francisco and spot a billboard with just five numbers. No company name. No explanation. Just:
100264, 76709, 1097, 675, 12084
That’s it. In a city where billboards are basically expensive Reddit posts hoping to go viral, this one was different. It had that perfect combination of simplicity and mystery that makes engineers lose sleep.
Someone cracked it within hours (because the internet never sleeps). The numbers were token IDs from OpenAI’s tokenizer. Decode them and you get: listenlabs.ai/puzzle.

And just like that, Listen Labs had created the kind of puzzle that gets shared in every engineering Slack channel and Discord server. The hook was perfect - accessible enough that anyone with basic knowledge could solve it, but mysterious enough to create genuine curiosity.
The Growth Hack Anatomy
I don’t just like programming with a monkey brain, I love clever marketing and honestly this was really, really good from a pure marketing perspective, Listen Labs nailed every viral coefficient multiplier:
- Mystery Phase: Cryptic billboard creates maximum speculation
- Discovery Phase: Token puzzle activates technical communities
- Challenge Phase: Berghain game provides addictive optimization loop
- Competition Phase: Leaderboard dynamics create retention through ego
They expected maybe 10 concurrent users. They got 30,000 in the first few hours, LOL power of X virallity with 1M+ views on Alfred’s announcement tweet.
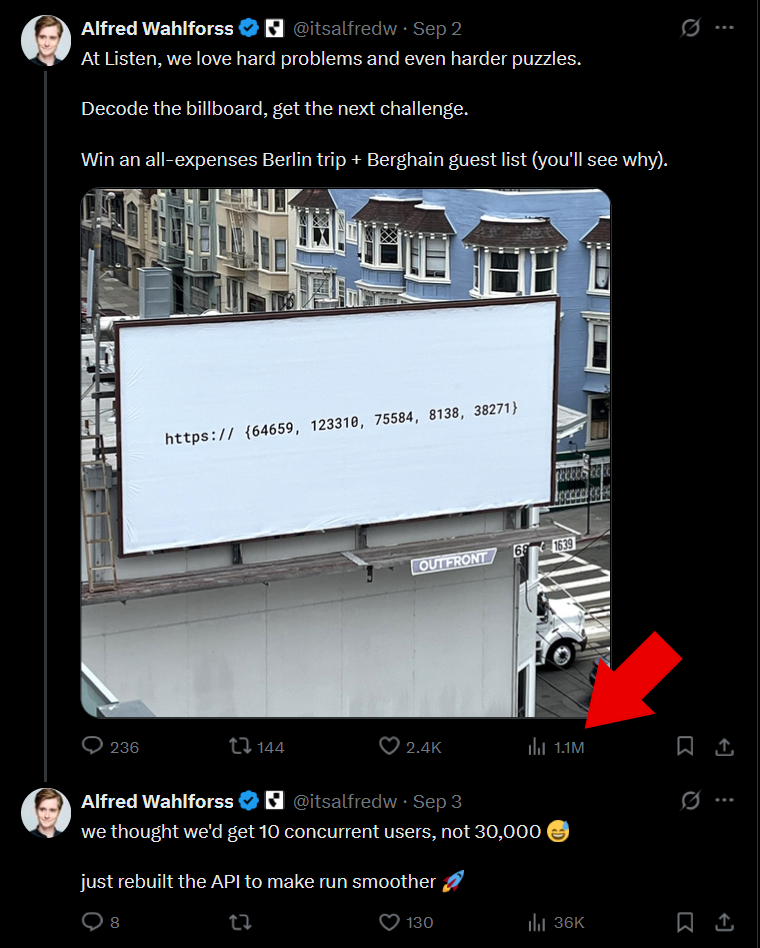
The servers immediately started buckling under the load. Error messages became as common as successful API calls. Rate limits kicked in. The community was simultaneously frustrated and more engaged because of it.
Because here’s the thing about scarcity - it works even when it’s accidental.
Welcome to Berghain (The Digital Version)
Hit that puzzle link and you’re suddenly the bouncer at Berlin’s most exclusive nightclub. Your mission seems simple: fill exactly 1,000 spots from a stream of random arrivals while meeting specific quotas. Don’t reject more than 20,000 people.
Oh, and the stakes?
Prize 🎉
The person at the top of the leaderboard Sept 15 6am PT will be the winner and get to go to Berghain - we fly you out! Also you get to interview with Listen ;)
Suddenly this wasn’t just an intellectual exercise. This was a trip to Berlin’s most exclusive nightclub plus a job interview at a hypergrowth startup. The prize was perfect - it attracted exactly the kind of people who would obsess over optimization problems.
Sounds straightforward, right? Literally an easy free trip.
LOL
Let me paint the picture of why this problem is mathematically evil:
You’re standing at the door of Berghain. People arrive one by one. Each person has binary attributes: young/old, well_dressed/casual, male/female, and others. You know the rough frequencies - about 32.3% are young, 32.3% are well_dressed.
But here’s the kicker: You must decide immediately. Accept or reject. No takebacks.
Your constraints for Scenario 1:
- Need at least 500 young people
- Need at least 500 well-dressed people
- Fill exactly 1,000 spots total
- Don’t reject more than 20,000 people (the lower the better)
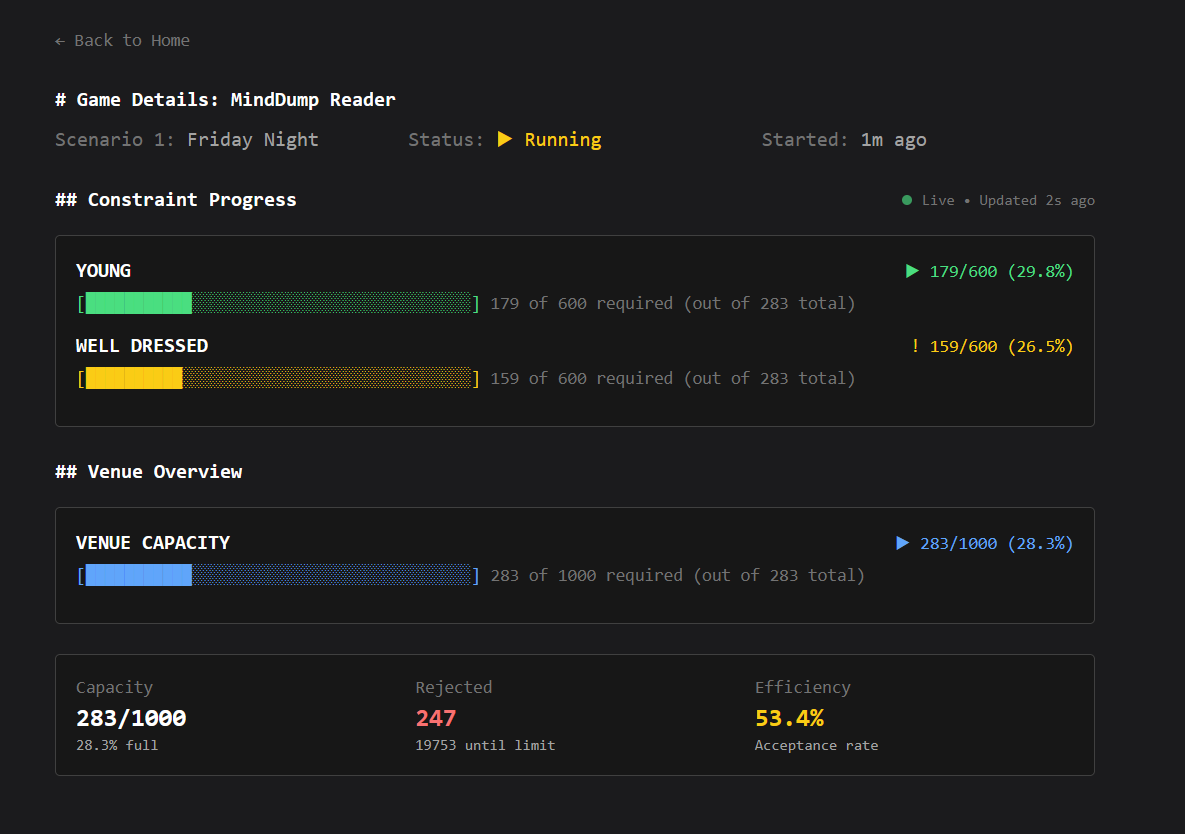
“Easy,” you think. “I’ll just accept everyone who helps with a constraint.”
Wrong.
The attributes are correlated. Some young people are also well_dressed. Accept too many of these “duals” early and you’ll overshoot one quota while undershooting the other. Reject too many and you’ll run out of people before meeting your minimums.
It’s a constrained optimization problem wrapped in a deceptively simple game. You’re essentially solving real-time resource allocation with incomplete information and irreversible decisions.
And then there were Scenarios 2 and 3, with 4 and 6 attributes respectively, where the state space explodes exponentially.
The Infrastructure Apocalypse
The first day was chaos.
Listen’s API was getting hammered by thousands of eager engineers. Response times went from milliseconds to seconds. Rate limits kicked in after just 10 parallel games. The error message “Application error: a server-side exception has occurred” was EXTREMELY frustrating.
Users were refreshing frantically. Discord servers spawned dedicated channels for coordinating attacks on the leaderboard. People were sharing VPN tips to bypass the rate limiting. The scarcity made everyone want it more.
Meanwhile, I was taking a different approach.
Going Local: Building My Own Berghain
While everyone else was fighting the overloaded API, I decided to build my own simulator. Same game mechanics, same statistical distributions, but I could run hundreds of games in parallel without waiting for servers to respond.
This is where the real obsession began.
My first approach was embarrassingly naive - what is basically a modified “greedy acceptance” algorithm:
def naive_decision(person_attributes, constraints, current_state):
# Accept if person helps with any unfulfilled constraint
for constraint in constraints:
if constraint.needed > 0 and person_attributes[constraint.attribute]:
return True
return False
Results: ~1,800 rejections. Terrible.
The problem was obvious in hindsight - I was being too greedy early on, accepting people who satisfied multiple constraints and leaving myself short on single-attribute coverage later.
But this was just the beginning.
The Algorithm Evolution
Over the next few days, I went through what I can only describe as an algorithmic evolution. Each approach taught me something new about the problem space, which btw now had way more people.
Phase 1: The UI Experiment
My first serious attempt was building a full web interface then gradually automate the decision-making.
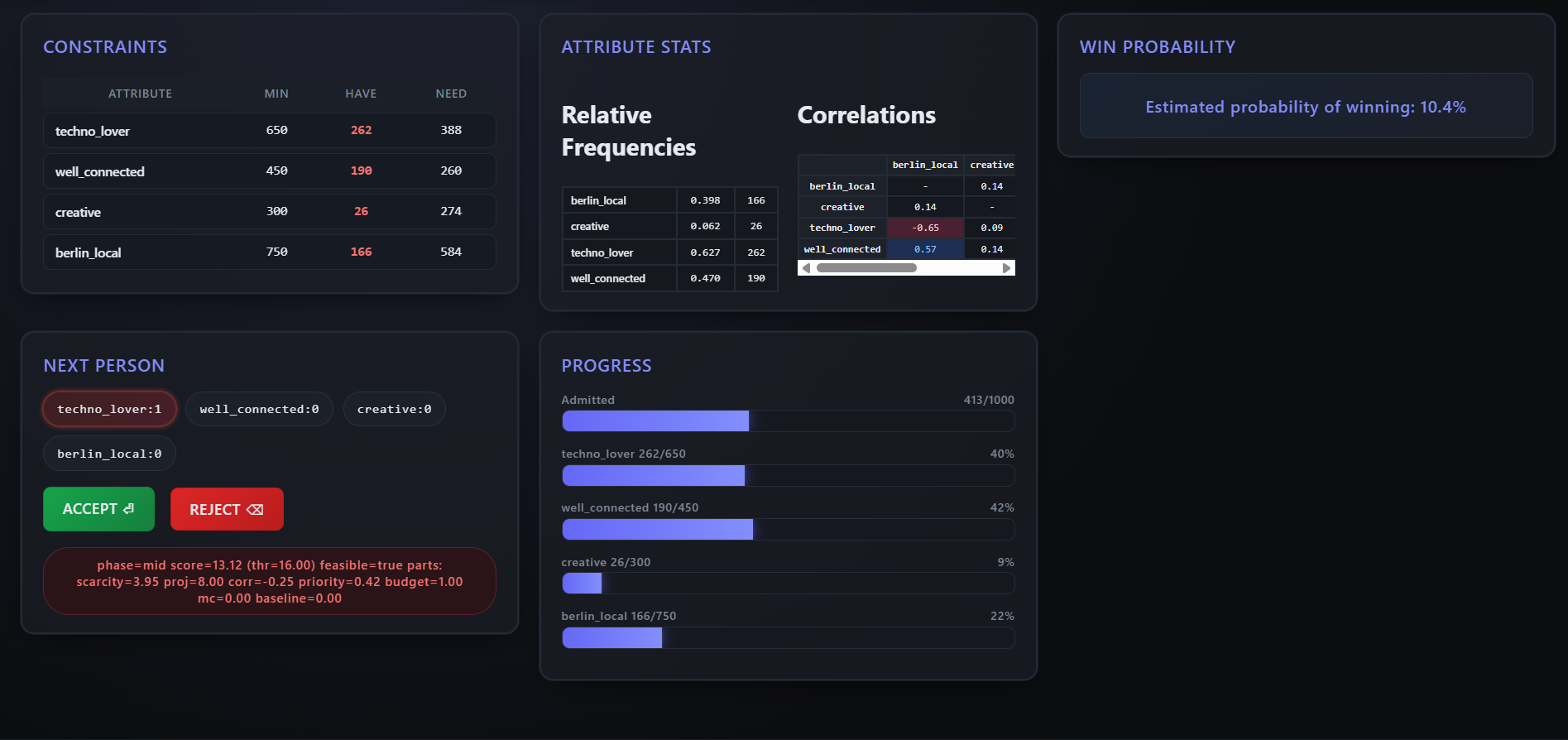
A bit of what the versions I was playing around with at this time looked like:
function heuristicSuggestAccept(person, state, constraints) {
// Accept if contributes to any deficit
for (let constraint of constraints) {
let remaining = constraint.minCount - state.admitted[constraint.attribute];
if (remaining > 0 && person.attributes[constraint.attribute]) {
return true;
}
}
// If all constraints met, accept everyone to fill remaining slots
return state.admittedCount < 1000;
}
This got me down to about ~1,200 rejections, but I knew there had to be better approaches.
Phase 2: The Mathematical Approach
Inspired by academic papers on admission control and resource allocation, I built a sophisticated system using Gaussian-copula modeling and linear programming.
The core insight: model the multivariate distribution of attributes using marginals and correlations, then solve for optimal acceptance probabilities.
def solve_acceptance_lp(types, weights, r_targets):
"""
Solve: max sum_u w_u * alpha_u
s.t. sum_u w_u * alpha_u * (types[u,k] - r_k) >= 0
0 <= alpha_u <= 1
"""
# Linear programming magic happens here
This approach was mathematically elegant - I was essentially solving for the dual variables in the optimization problem, using Hoeffding bounds for safety buffers, and re-solving periodically to stay on track.
Results: ~900 rejections. Much better!
But the complexity was enormous. The Gaussian-copula modeling alone required 200,000 Monte Carlo samples to get stable estimates, too overkill and not as great.
Phase 3: The Pragmatic Iteration
Sometimes simple is better. I stripped away the mathematical complexity and focused on engineering multiple variations of threshold-based algorithms.
def algo_03_decision(constraints, statistics, correlations,
admitted_count, rejected_count, next_person,
accepted_count, random_acceptance_rate=0.0):
# Dynamic risk threshold - lenient early, stricter late
remaining_spots = 1000 - admitted_count
progress = admitted_count / 1000.0
# Auto-accept for scarce attributes
for constraint in constraints:
remaining_needed = constraint['minCount'] - accepted_count.get(constraint['attribute'], 0)
if remaining_needed > 0:
scarcity_ratio = remaining_needed / remaining_spots
if scarcity_ratio > 0.6: # Critical shortage
if next_person['attributes'][constraint['attribute']]:
return True
# Multi-cover reward - prefer people satisfying multiple constraints
coverage_score = sum(1 for c in constraints
if next_person['attributes'][c['attribute']] and
(c['minCount'] - accepted_count.get(c['attribute'], 0)) > 0)
# Threshold decision with mild randomness early
base_threshold = 0.7 - (progress * 0.3) # More lenient early
if coverage_score >= 2:
return True
elif coverage_score == 1:
return random.random() < (base_threshold + random_acceptance_rate)
return False
I created multiple variants (algo-02-1, algo-02-2, algo-02-3, algo-03) and used a coordination system where multiple terminals could work together, sharing results through locked JSON files to avoid testing the same parameters.
Results: ~800 rejections consistently.
The problem wasn’t just with the algorithms at this point. You see, it wasn’t always just about how polished your approach is, 5 iterations taught me that
A large chunk of the games at that point were based around your luck and the quality of people you get that night, people ran 50+ games trying to get the best scenarios with hopes of these and honestly, it’s really hard to compete with that sort of muscle power.
This was the point where I went back to late 30s in ranking and I honestly stopped. 3 days worth of runs and I was satisfied with what I had come up with.
The Algorithm Zoo
By the end, I had built what can only be described as an algorithm zoo:
- UI-based manual play with auto-suggestions
- Gaussian-copula mathematical modeling with LP solving
- Multi-variant threshold algorithms with parameter sweeps
- Rarity-based scoring with correlation adjustments
- Dual-variable tracking inspired by the winner’s approach
Each approach taught me something different about the problem space. The manual play gave intuition. The mathematical modeling taught me about the theoretical bounds. The pragmatic iterations showed me the value of engineering over theory.
At this point, something interesting happened. Listen Labs started reaching out to top performers on the leaderboard:
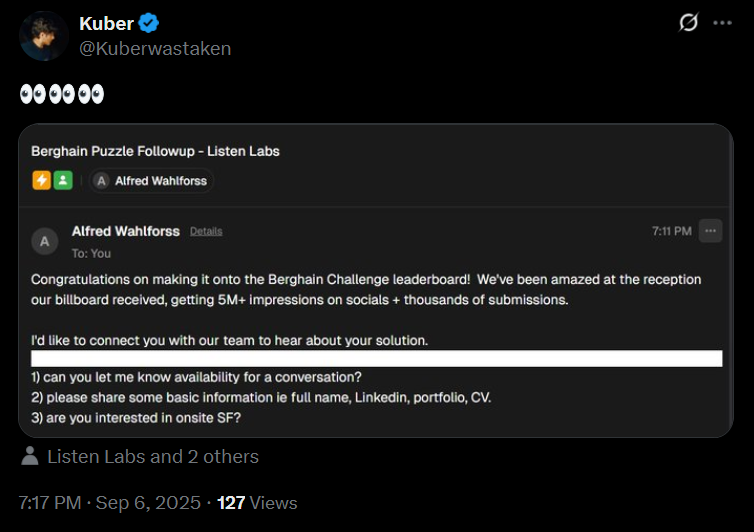
Getting this email at #16 was validation that my approach was competitive. But it also made me curious about what the very top performers were doing differently.
The Hidden GitHub Treasure Hunt
One of the most fascinating aspects was that many people published their solutions on GitHub but left their player IDs hardcoded in the code. This created an unintentional transparency - you could see exactly which algorithms were achieving which rankings if you searched up the baseurl of “https://berghain.challenges.listenlabs.ai/” of course this had no other issues since the official communications were done through mail anyways.
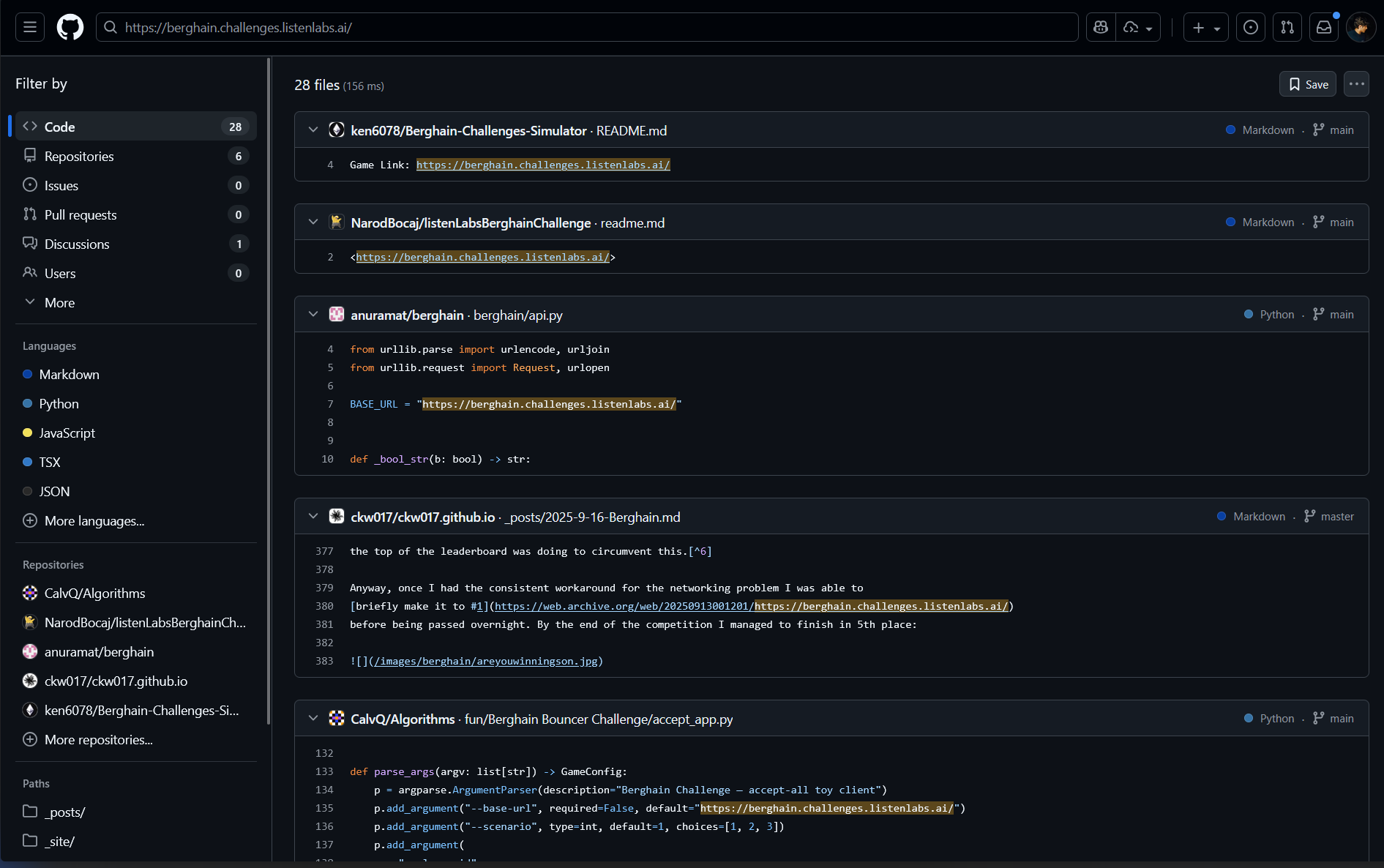
I spent hours analyzing repositories, correlating commit timestamps with leaderboard changes, and understanding how different approaches performed across scenarios. It was like having access to a real-time research lab with thousands of parallel experiments.
Studying The Masters
John’s solution was a thing of beauty. For context, I mentioned John in a post I made about a Berghain run for fun since he was #2 on the leaderboard then and funnily enough he replied on the post. We talked for a while about a lot of parts of the contest and later he dropped a nice dissection of his approach on X
In case you’re curious you can go to the link below, it’s a great read. https://x.com/haskallcurry/status/1968365914468008224
But I’ll dissect down the basics.
For Scenario 1 (just two traits), he solved it exactly using dynamic programming. The DP table was around a gigabyte, but it gave him the theoretical optimum - the absolute best possible expected number of rejections.
But for Scenarios 2 and 3 (4 and 6 traits respectively), the DP table wouldn’t fit in memory. So John turned to the continuous form. His key insight:
“As the number of people gets large, only the relative ratios between the numbers matter”
This led him to a differential equation representation of the problem. Instead of tracking absolute counts, he could work with relative ratios and solve for optimal policies in continuous space.
When I saw his visualizations - the smooth trajectory showing optimal policy decisions (accept all, accept only trait 1, accept only trait 2, accept both traits) - I realized how cool it was
He also confirmed the luck problem I spoke of:
This luck factor was something everyone dealt with. Some people had beefier hardware and could run more parallel sessions. Others got better random sequences. The combination of algorithmic skill and computational resources created an interesting dynamic.
Dissecting Victory - David Heineman’s Dual Threshold Solver
When David Heineman released his winning repository, I dove deep into understanding what made it so effective. His DualThresholdSolver was a masterclass in pragmatic optimization.
(btw he has a really cool looking site lol)
The core algorithm used dual variables with scenario-specific parameter tuning:
SCENARIO_DEFAULTS = {
1: {
"z0": 3.0, # Initial threshold multiplier
"z1": 0.3, # Late-game threshold
"eta0": 0.7, # Base acceptance rate
"lambda_max": 16.0, # Maximum dual variable
"endgame_R": 10, # Endgame remaining count
"use_rarity": True, # Factor in attribute rarity
},
2: {
"z0": 2.5,
"z1": 0.5,
"eta0": 0.55,
"lambda_max": 12.5,
"endgame_R": 32,
"use_rarity": False,
},
3: {
"z0": 2.5,
"z1": 0.5,
"eta0": 0.77,
"lambda_max": 12.0,
"endgame_R": 33,
"use_rarity": False,
},
}
The elegance was in the parameter sweeps. Instead of trying to build one universal algorithm, David tuned specific parameters for each scenario through extensive experimentation.
His approach also included:
- Dual variable tracking for each constraint
- Rarity-based scoring (for Scenario 1 only)
- Endgame detection with different strategies for final decisions
- Safety margins to avoid constraint violations
Looking at this code, I realized why my complex mathematical approaches hadn’t performed better - sometimes engineering beats theory, or well, engineering that’s coupled with a lot of playthroughs.
The Rankings Rollercoaster
400 → 313 → 87 → 37 → 34 → 16… → 87
Getting to #16 out of tens of thousands of participants was surreal. I had no formal algorithmic background - I was just someone who enjoyed optimization problems and wasn’t afraid to iterate rapidly.
But the ranking also shows the brutal nature of optimization competitions. One day you’re in the top 20, the next day someone discovers a new approach and you’re back down.
The Community That Made It Special
What made this challenge truly special wasn’t just the problem - it was the community that formed around it.
GitHub repositories popped up daily with new algorithms, people tweeted a lot, played so many games concurrently that it was insane.
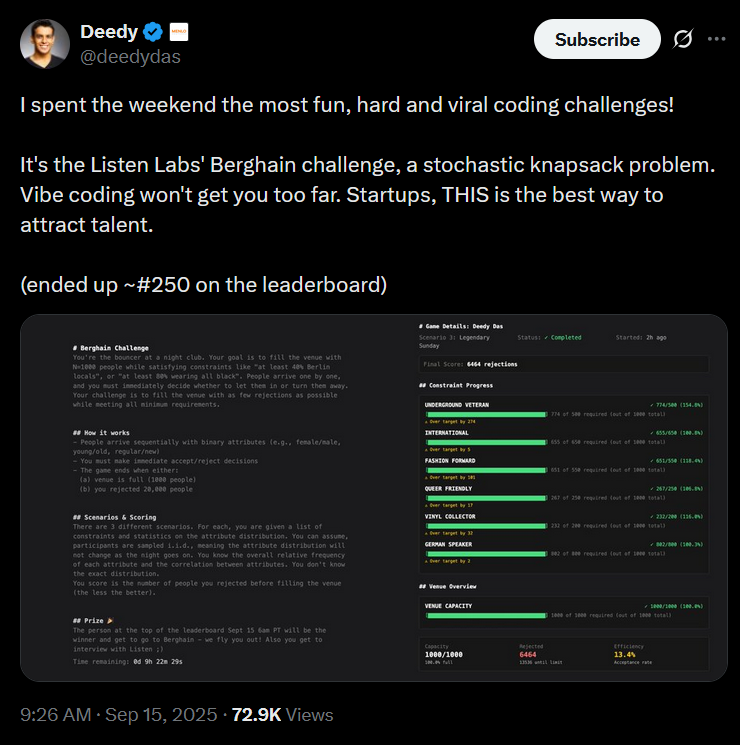
John and I ended up in some DM conversations about approaches. Despite being competition, the community was incredibly collaborative. People shared insights freely, celebrated each other’s breakthroughs, and collectively pushed the boundaries of what was possible.
This wasn’t grinding LeetCode or memorizing algorithms for interviews. This was pure problem-solving - the kind where you lose track of time because you’re genuinely excited about the next iteration.
The Rate Limiting Wars
As the challenge progressed, the infrastructure constraints became part of the game itself. Listen implemented increasingly aggressive rate limiting:
-
Maximum 10 parallel games
-
Temporary blacklists for 8+ concurrent sessions
-
10-12 hour cooldowns for “abuse”
But the community adapted. VPN techniques emerged. People coordinated game times to avoid peak load. Some discovered that different geographic regions had different limits.
I got blacklisted twice - once for running too many parallel tests, once for what I suspect was rapid API calls during debugging. Each blacklist was a 12-hour timeout that felt like an eternity when you’re in optimization flow state.
The irony was beautiful - the technical constraints meant to manage load became additional puzzles to solve.
What I Learned About Optimization
This challenge taught me more about practical optimization than any academic course could:
1. Simple Often Beats Complex
My most mathematically sophisticated approach (Gaussian-copula with linear programming) was outperformed by simpler threshold-based algorithms. Complexity is only valuable if it solves the right problem.
2. Parameter Tuning Matters More Than Algorithms
David’s winning approach wasn’t revolutionary - it was excellently tuned. The difference between good and great often comes down to careful experimentation with parameter values.
3. Iteration Speed Trumps Perfection
Being able to test 10 variations in an hour was more valuable than spending a day perfecting one approach. Fast feedback loops enable rapid learning.
4. Domain Knowledge Has Unexpected Sources
Some of the best insights came from conversations with other participants, not from textbooks. The collective intelligence of an engaged community is remarkable.
5. Constraints Can Be Features
The API rate limiting that frustrated everyone actually improved the experience by creating scarcity and preventing brute-force approaches from dominating.
Why This Matters
Listen Labs created something remarkable - a distributed research experiment with 30,000 participants, all attacking the same optimization problem with complete transparency about results.
The collective compute power was staggering. The diversity of approaches was inspiring. The community that formed was genuine.
But more importantly, this was a reminder of why I love programming. Not for interviews or career advancement, but for the pure joy of making something work better. Of turning 1,200 rejections into 800, then 600, then wondering if you can squeeze out just a few more.
In a world of algorithmic interviews and competitive programming focused on memorization, the Berghain Challenge was different. It rewarded creativity, iteration, and practical problem-solving. It brought together people who genuinely love what they do.
The Future of Collaborative Competition
What excites me most about this experience is what it suggests about the future of technical challenges:
-
Real-time collaboration during competition
-
Open-source approaches with transparent ranking systems
-
Community-driven learning rather than isolated grinding
-
Practical optimization over abstract algorithmic puzzles
The Berghain Challenge proved that technical competitions can be both rigorous and genuinely enjoyable. They can create communities instead of just rankings.
Final Rankings and Reflections
I never expected to win - that wasn’t the point. Going from algorithmic newbie to #16 out of 30,000 participants was already beyond my wildest expectations.
But the real victory was the journey. The late nights debugging correlation matrices. The excitement of dropping from 900 rejections to 850. The conversations with brilliant people who were equally obsessed.
David took #1 with his pragmatic dual-threshold solver. John peaked at #2 initially, later going doing, just as I did and I peaked at #16 with my multi-algorithm iteration approach and dropped back to #82 during my final experimentation phase.
And you know what? I regret nothing about these haha, it was actually fun.
Because that’s what made this challenge special - it wasn’t about the destination, it was about the journey. It was about falling in love with optimization all over again.
Listen Labs set out to hire technical talent with a clever growth hack. What they accidentally created was a reminder of why we all fell in love with programming in the first place. And sometimes, that’s worth more than any ranking.
The code for all my approaches is available across the different project folders on GitHub at https://github.com/Kuberwastaken/Berghain. Feel free to explore, iterate, and improve. After all, the best optimization problems are the ones that keep evolving. You can still do the challenges - just not get to Berghain with them, welp.