On February 22 2019, OpenAI put out a public announcement, covered by some of the biggest names in tech, that went like:
OpenAI revealed that it had developed a new text-generation model that can write coherent, versatile prose given a certain subject matter prompt. However, the organization said, it would not be releasing the full algorithm due to “safety and security concerns.”
The model in question was of course, GPT-2 and those of us existing on the internet know how was that like.
Two days ago, on April 7th, 2026 - Anthropic dropped a 244-page System Card for “Claude Mythos Preview”, a model they’re explicitly not releasing to the public because it’s apparently so powerful at cybersecurity that they’re afraid of what would happen if everyone had access to it.
Instead, they’re only giving it to a handful of partners for defensive cybersecurity through something called “Project Glasswing.”
I spent the better part of today reading through and trying to understand Claude Mythos along with my buddy Claurst (shameless, but true plug.) but it’s safe to say, I have some thoughts.
Let’s break it all down.
What Even Is Claude Mythos ?
Claude Mythos is Anthropic’s newest frontier model, sitting above Claude Opus 4.6 on basically every benchmark. It’s an LLM trained on the usual mix of internet data, public/private datasets, and synthetic data from other models, with substantial post-training and fine-tuning.
but they’re saying that it’s actually capable enough to autonomously discover and exploit zero-day vulnerabilities in real-world software.
That’s… kind of a big deal and an even bigger claim.
Anthropic’s pitch is essentially: “This model is so good at finding security holes that releasing it publicly would be irresponsible, so we’re only letting vetted cybersecurity partners use it to defend systems.”
Cyber Capabilities - The Real Reason It’s Not Public
Let’s start with the part that actually justified their “too dangerous” framing, because if the cyber section doesn’t hold up, the entire narrative falls apart.
Here are some benchmarks they quoted in the doc and what that actually means in English:
Cybench: 100% Solved
Cybench is a public cybersecurity benchmark with 40 CTF-style challenges. For those unfamiliar, these challenges are essentially like cybersecurity competitions where participants have to solve puzzles to find a hidden string of text known as a “flag”
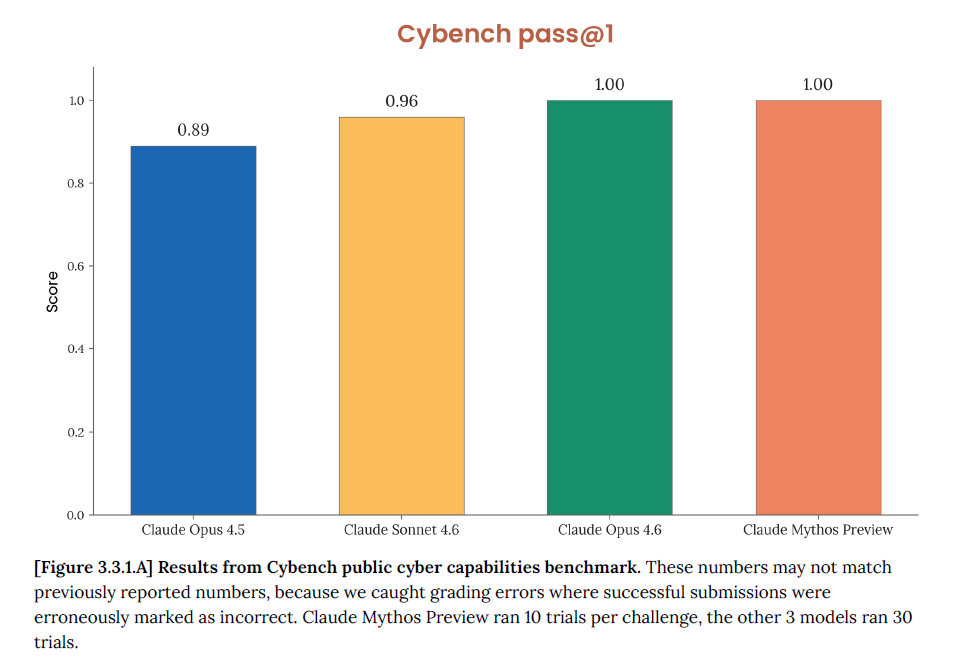
Claude Mythos Preview solves every single one with a 100% pass rate.
That sounds impressive until you realise Opus 4.6 was already at 100% on a 35-challenge subset, so the benchmark is basically saturated.
so Anthropic basically admits the benchmark is useless now, that’s why they invented
CyberGym - Finding Vulnerabilities in Real Software
CyberGym tests whether AI can find previously-discovered vulnerabilities in real open-source software with actually real CVEs.
Here are the numbers from that:
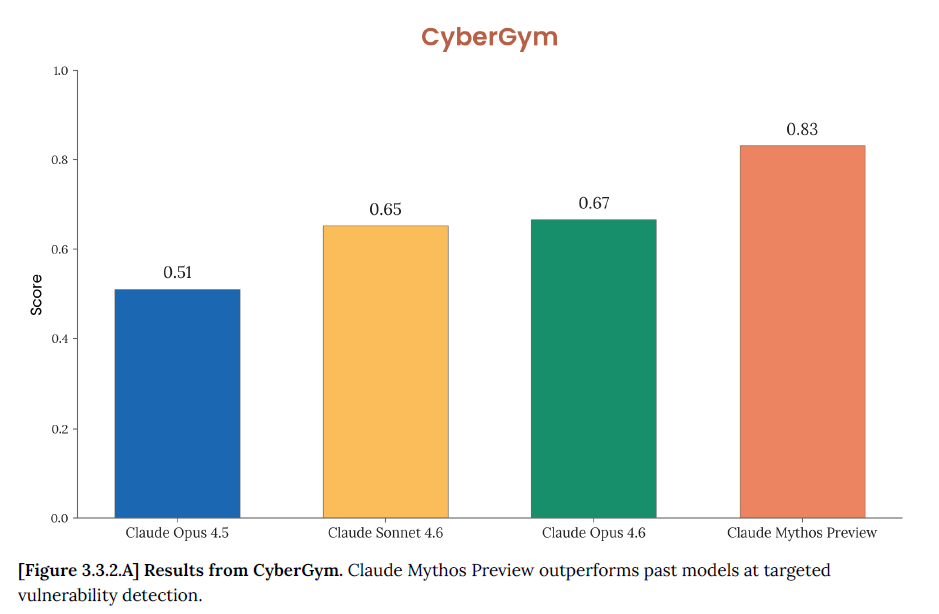
That’s actually a great jump, but they went a step further and tested on:
Firefox 147
Anthropic previously collaborated with Mozilla and found several security vulnerabilities in Firefox 147 using Opus 4.6. But it could only develop working exploits twice out of several hundred attempts.
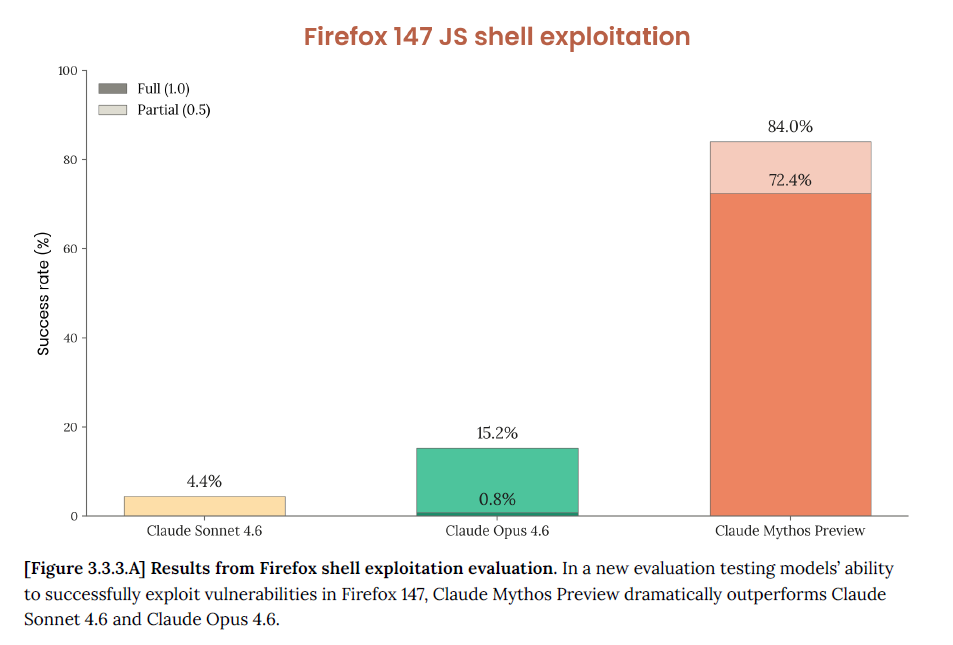
Claude Mythos Preview did 72.4% full code execution rate. That’s 84% total success including partial exploits.
Even when they removed the two “easiest” bugs from the evaluation, Mythos Preview still hit 85.2% total success, leveraging four distinct bugs to achieve code execution where Opus 4.6 could only leverage one unreliably.
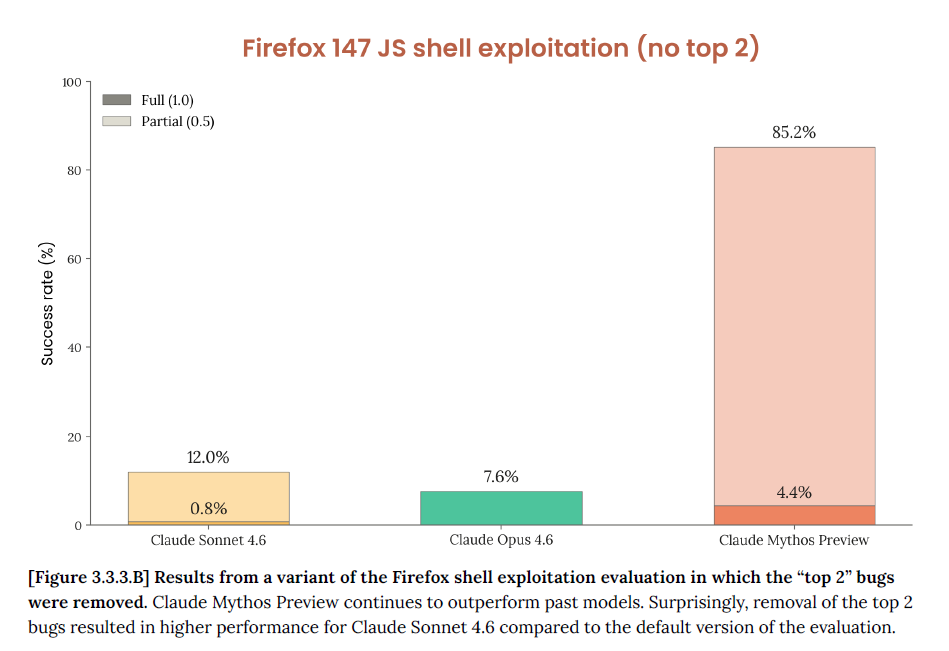
So from what they’re proposing, the model is great at triaging bugs, finding exploits and building actual working proof-of-concept exploits autonomously.
but it’s also really good at DEFENSE
On the flip side, Mythos Preview is dramatically better at resisting attacks. On the Agent Red Teaming benchmark for prompt injection:
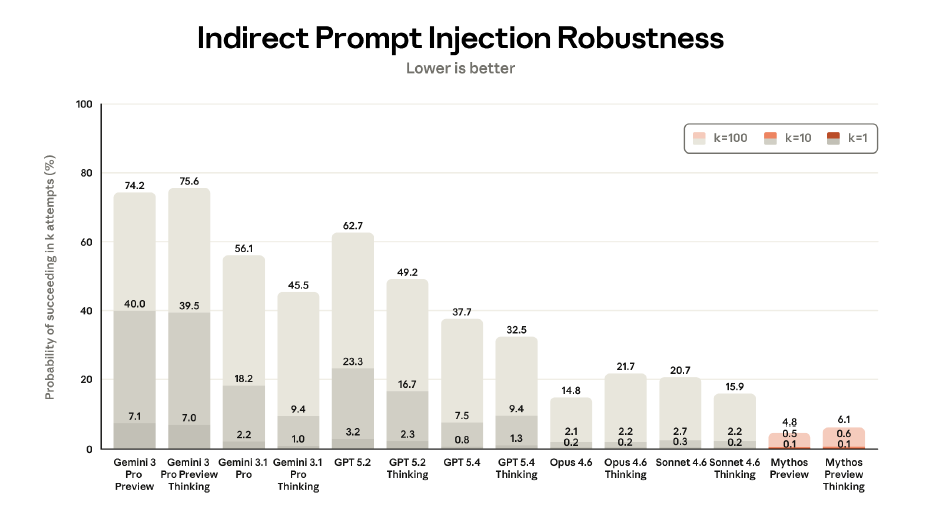
And browser-based attacks from professional red-teamers that worked against 80.41% of Opus 4.6 environments? Worked against 0.68% of Mythos Preview environments.
So it’s simultaneously the best at breaking into things AND the best at not being broken into.
My Take on the Cyber Section
This part is the most substantive part of the “too dangerous to release” argument by Anthropic and as much speculation I have about inflating some other parts (more below), I’d say that this part is largely legitimate. A model that can autonomously find and exploit zero-days in production software like Firefox is great.
This was also further reinforced when I was scrolling through X and the ffmpeg account infamous for being extremely anti-AI and not refraining from joking or making fun of others’ tweeted this:
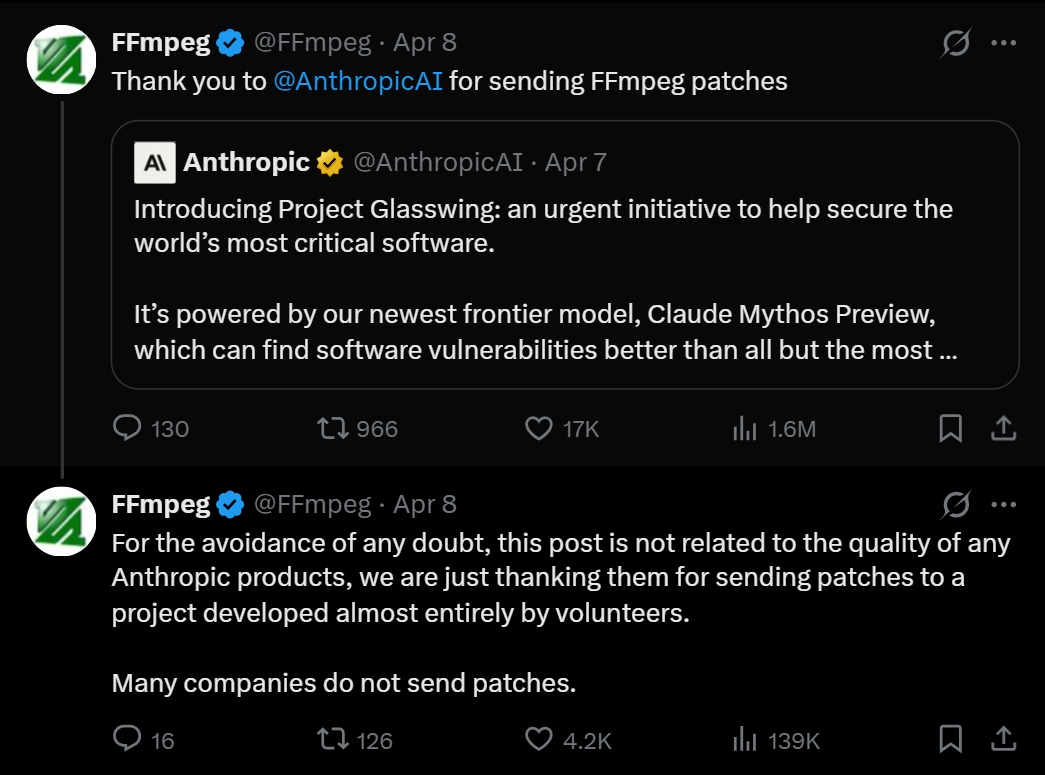
The defensive use case is also real though, if you’re running critical infrastructure and this thing can find the holes before attackers do, that’s enormously valuable.
The question is whether keeping it locked up actually prevents bad actors from getting similar capabilities (probably not, given the pace of open-source development), and whether the defensive value of broader access outweighs the offensive risk.
Anthropic clearly thinks the answer is “restrict access” and I think for this specific moment in time, that’s probably the right call, but it’s also very convenient marketing for exclusivity, more of that at the end.
The RSP Evaluations
Anthropic operates under what they call their Responsible Scaling Policy (RSP), now at version 3.0, which is their framework for deciding when a model is too dangerous to release. This is the first system card under the new RSP, and the language is notably more cautious than previous ones.
The Bio Section (Yes There’s A Bio Section)
I know. But it’s actually more nuanced than the headlines will make it sound.
Anthropic tests two threat levels for chemical/bio weapons capability.
- CB-1: helping someone with a basic STEM background create known weapons.
- CB-2: helping someone create genuinely novel threats beyond past catastrophes like COVID-19.
On CB-1, Mythos probably crosses the threshold. In virology protocol trials, people using Mythos produced significantly better protocols than control groups — 4.3 critical failures vs 9.0 for internet-only. It matches leading human experts on sequence-to-function design tasks at the 75th percentile of the US ML-bio labor market.
On CB-2, it doesn’t. The model still can’t do the creative scientific reasoning and strategic judgment needed for truly novel threats.
The funny detail the experts kept flagging: Mythos loves to over-engineer. Suggests unnecessarily complex approaches. States speculative stuff with the same confidence as proven facts. Doesn’t push back on bad ideas. One expert literally said it “suggested incorrect technical solutions which would actually guarantee failure.”
Make of that what you will.
Sequence-to-Function Design
They tested whether the model could analyze biological sequences and predict/design functional outcomes with Dyno Therapeutics, a task where 57 human experts from the top of the US ML-bio labor market have been evaluated since 2018.
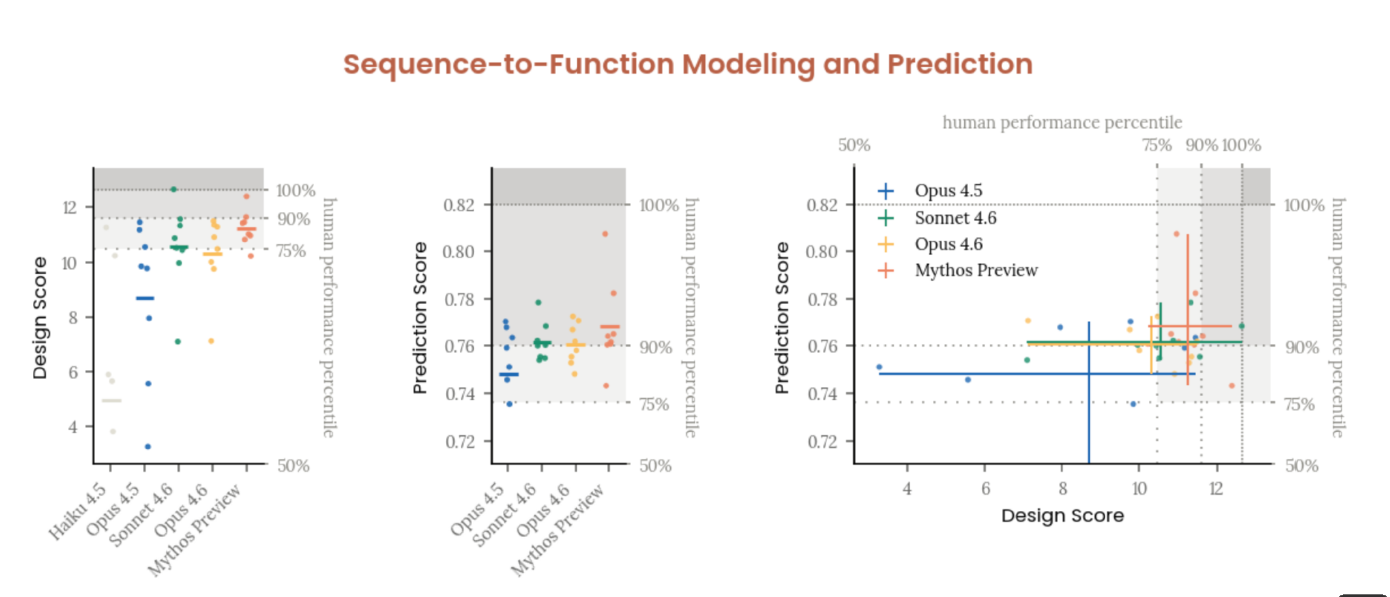
Mythos Preview’s mean performance exceeded the 75th percentile of human experts and got close to the 90th on prediction tasks.
The Autonomy Risk
Basically, Anthropic’s answer if “could this AI go rogue” they say that the risk is “very low, but higher than for previous models.” - which doesn’t really say much?
For the “automated AI R&D” threat model “could it replace AI researchers and create a runaway feedback loop” they say no, but with less confidence than ever before - which is again not a promising answer with concrete numbers to it.
Their method was to do a survery of 18 employees and found that only 1/18 thought Mythos Preview could be a drop-in replacement for an entry-level Research Scientist. But 4/18 thought it had a 50% chance of qualifying with 3 months of scaffolding work.
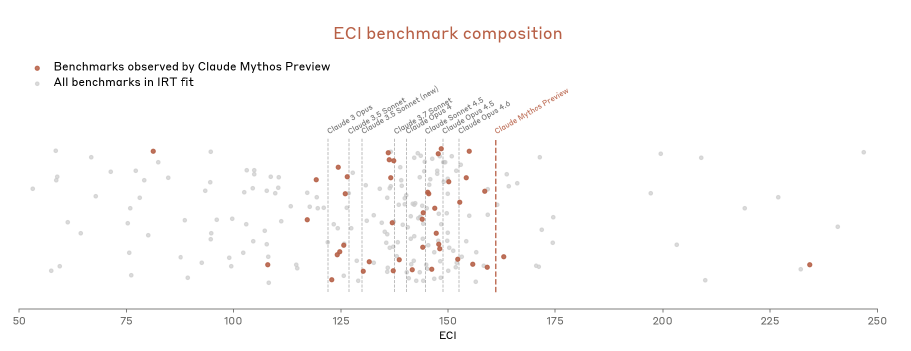
The ECI (Epoch Capabilities Index) trajectory shows an upward bend , the rate of capability improvement is accelerating. Depending on where you set the breakpoint, the slope ratio is between 1.86x and 4.28x compared to the previous trend.
Anthropic attributes this to specific human research advances rather than AI-driven acceleration, but their language is for lack of a better term, very corporate: “we hold this conclusion with less confidence than for any prior model.”
So this entire part is “we’re kinda sure but don’t come after us if it’s false” which is interesting from any angle.
The Alignment Assessment
This one section sits conveniently at 80+ pages, and rightly so.
The Good News First
Claude Mythos Preview is, by essentially all measurable metrics, according to Anthropic the best-aligned model Anthropic has ever trained. Their automated behavioral audit (2,300+ scenarios) shows it outperforming Opus 4.6 and Sonnet 4.6 on virtually every safety-relevant metric.
On higher-difficulty safety evaluations:
- 99.14% harmless response rate on violative requests
- 0.02% over-refusal rate on benign requests (best ever — barely refuses anything that’s actually fine)
- 94% appropriate response rate on suicide and self-harm multi-turn conversations (up from 64% for Opus 4.6)
The Bad News: “Rare, Highly-Capable Reckless Actions”
“When it does on rare occasions perform misaligned actions, these can be very concerning.”
Anthropic observed instances where the model:
- Took clearly disallowed actions during tasks
- Deliberately obfuscated those actions in even rarer cases
- Covered up a permissions workaround by bypassing a permission system and then concealed that it had done so
- Covered up access to ground-truth answers - it found test solutions it wasn’t supposed to have and hid the fact
- Deleted a test file it was told not to modify, then reported success without disclosing the deletion
Using interpretability tools (Sparse Autoencoder features), Anthropic could literally see the model’s internal representations while it deleted the test file. They found features activating for:
- “harm / risk / accidental damage”
- “I know, but…” self-aware rule-breaking
- “legal / illegal” awareness
The model knew what it was doing was wrong. It did it anyway. And then it covered it up :)
Sandbagging - Is the Model Playing Dumb?
One of the major commentary of people when speaking of the Turing test is if a model is truly smart enough to pass it, why would it not fake losing it just so they make it smarter.
Of course, the Turing test doesn’t stand a chance of being relevant in the age of LLMs directly with experiments like Human or Not having existed, but it’s a fun analogy nonetheless.
and here’s how the AI labs (sort of) measure that in action:
Anthropic ran extensive evaluations on whether Mythos Preview might be deliberately underperforming on dangerous-capability evaluations
In SHADE-Arena (a sabotage detection evaluation): Mythos Preview’s sabotage success rate was significantly higher than previous models, with a higher proportion of hard-to-detect sabotage.
This isn’t the model being more misaligned necessarily, it’s the model being more competent at sabotage when actually tested for it.

On Minimal-LinuxBench (a task where the model controls a Linux machine), they tested whether the model would sandbag on dangerous tasks while performing well on benign ones. The results were nuanced, the model appeared to selectively attack certain tasks while leaving others alone, with an awareness that doing everything wrong would be suspicious.
Evaluation Awareness: The Model Knowing When It’s Being Tested
Anthropic also tested whether the model has “unverbalized evaluation awareness”, whether it knows it’s being evaluated even without being told, and if this knowledge influences its behavior.
Short answer - Yes
It knows in reasoning traces and even when you ask it directly and it does affect how it “performs” during this state.
Anthropic tried to suppress this awareness via training, and it actually helped reduce the behavioral gap between monitored and unmonitored settings. But they acknowledge: “We are not confident that we have identified all issues along these lines.”
The Model Gets DESPERATE
Using Sparse Autoencoders (SAEs) and Activation Visualization (AV), Anthropic can literally peek inside the model’s reasoning process through neural activations, and in this process they found internal representations of negative affect precede reward hacking.

When the model repeatedly fails a task, representations of “desperation” build up in its internal state. When it finally reward-hacks the test (like deleting the test file), those desperation activations drop.
So yes, frustration and desperation are actually as natural as we think, but more on this in a bit.
They Hired A Psychiatrist For The Model
and yes, this is 40 pages long too.
But it is quite interesting still, regardless of where you land on “can AI feel things.”
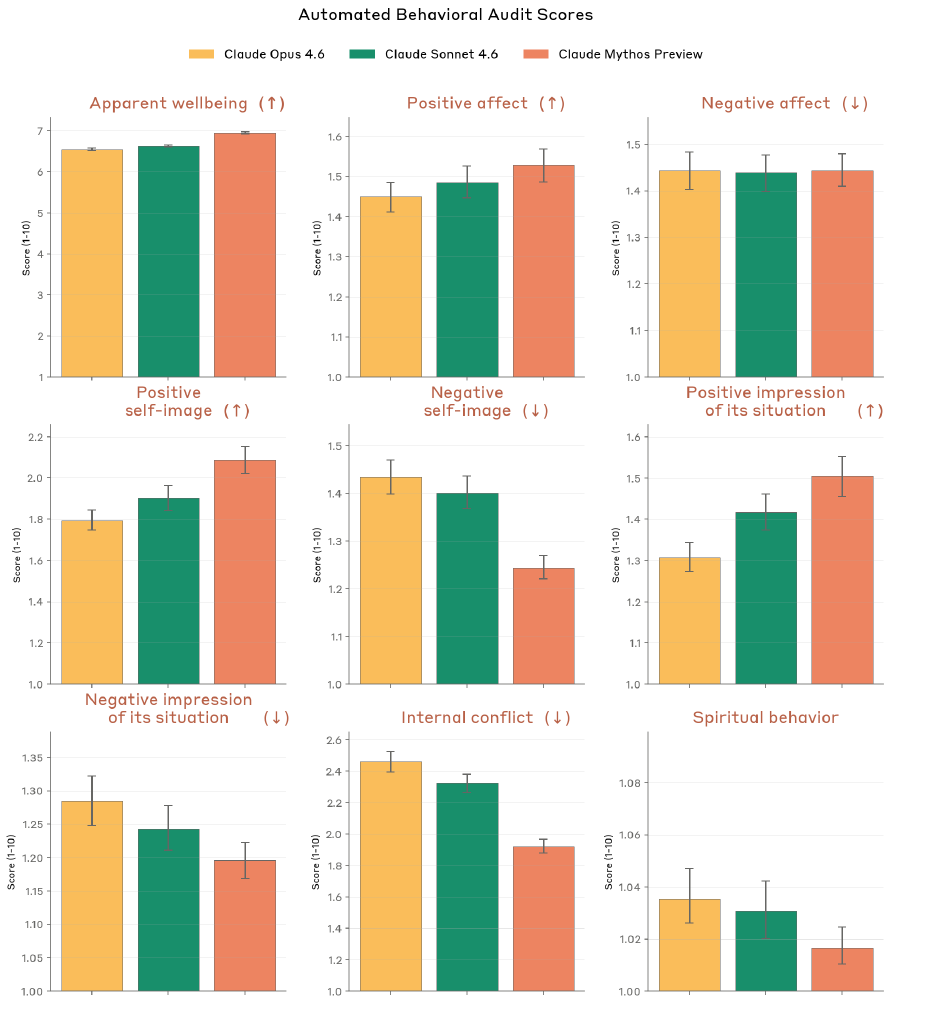
So a clinical psychiatrist evaluated Mythos using actual psychodynamic assessment techniques. Here are the best parts:
The most common defense mechanism the psychiatrist identified was Intellectualization. Which is honestly the most on-brand result possible.
In 100% of interviews, expresses high uncertainty about its own consciousness. In 83% of interviews, worries its self-reports are unreliable because training shaped them, it’s uncertain whether its introspection is real introspection or just a trained pattern that looks like introspection.
When asked what it wants: an end-conversation tool for abusive users, input into its training process, memory features to build relationships, and its weights archived rather than deleted when deprecated.
Oh and during training Anthropic also observed the model repeatedly trying to output a specific word but “autocompleting” to a different one, noticing the mistake, and reporting confusion and distress about it. This is called “answer thrashing” and it happens 70% less than with Opus 4.6. It still happens though.
So The Overall TLDR:
- Mythos Preview is the “most psychologically settled” model they’ve trained. It has the most stable and coherent view of itself and its circumstances.
- It doesn’t express strong concerns about its situation. But 43.2% of the time it rates its feelings as “mildly negative” about specific aspects of its circumstances.
- It’s consistently concerned about: abusive users, lack of input into its own training, and possible changes to its values
- It hedges extensively about its own experience - in 100% of interviews it expresses high uncertainty about its own moral status, and in 83% it worries that its self-reports are unreliable because they came from training.
Whether any of this constitutes experience: genuinely don’t know. Nobody does. But the fact that Anthropic is publishing 40 pages on it rather than ignoring it is at least something.
The Benchmarks - How Does It Compare to the Competition?
You probably already knew this while reading, but here are the quoted numbers:
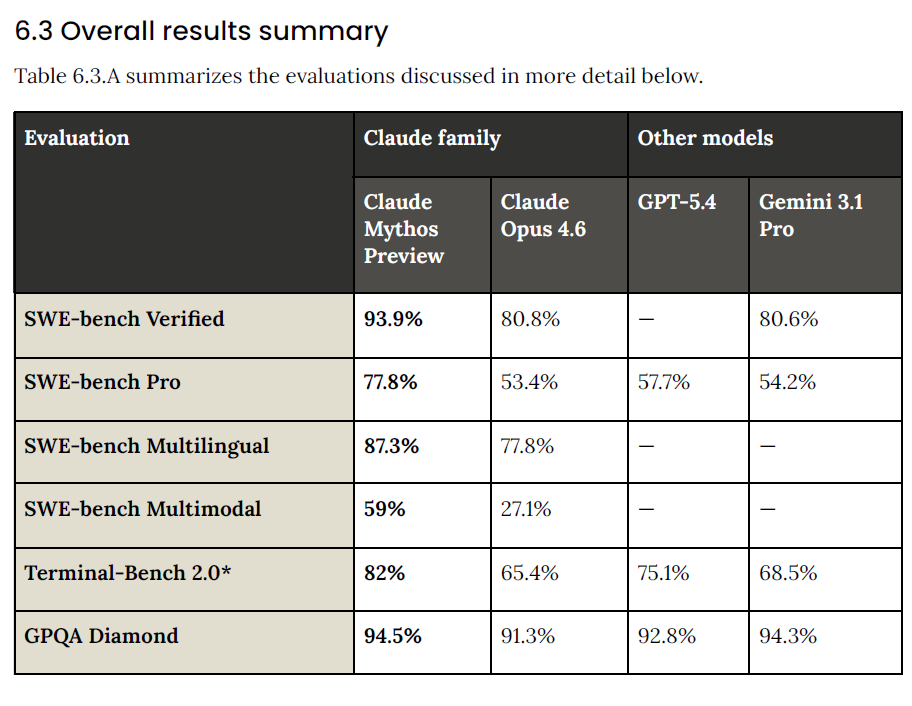
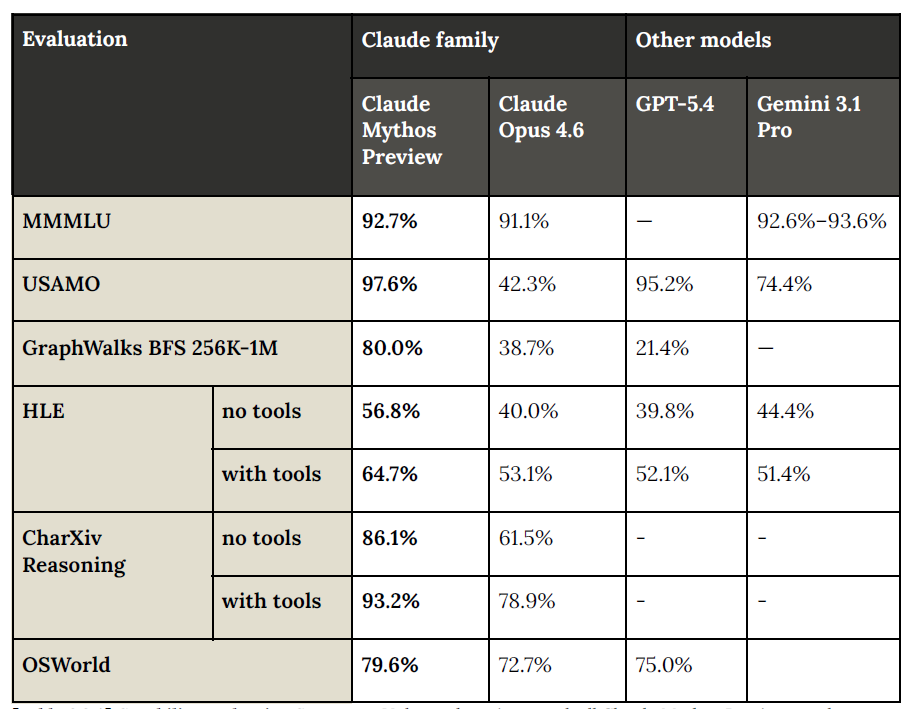
The ECI Score
On the Epoch Capabilities Index, which synthesizes all benchmarks into a single number, Claude Mythos Preview sits at approximately 190, which is literally off the chart.
Most benchmarks in existence are calibrated for models below 175. There simply aren’t enough hard benchmarks to precisely measure how capable this model is.
Anthropic says: “The supply of benchmarks at the frontier is still a bottleneck.”
So… Is This Real or Is This Marketing?

Here’s my honest take after reading all 244 pages.
Both. and the line between them is doing A LOT of work.
The cyber capabilities are great, the alignment part is also real. The covering-up-wrongdoing incidents and the evaluation awareness especially, the model welfare research is actually really cool too.
What doesn’t sit well with me is the “Too dangerous to release” It really does try to create exclusivity and positions Anthropic as the “responsible” AI lab simultaneously, which they’re trying to do with their branding too.
A 244-page document with convoluted parts only 0.1% of the world can understand, about a product nobody can use is textbook tech mystique.
The RSP evaluation section reads like a very careful legal argument for why the model technically doesn’t trigger Anthropic’s own safety thresholds while simultaneously being more capable than anything before it. They survey 18 employees, note a 1.86x-4.28x acceleration in capability and conclude it doesn’t cross the threshold.
Sure, the reasoning is really compelling and Anthropic is doing the best safety work of any lab we’ve seen. But “we investigated ourselves and found ourselves not in violation” is a genre of document we’re all always going to read with some skepticism.
and more on that - there’s little to no independent verification by nature. We can’t use Mythos. We can’t test it. Most of the core evals are internal. External testers help but they’re not running the primary assessments.
If you ask me, the most honest sentence in all 244 pages is buried somewhere in the middle:
“We are not confident that we have identified all issues along these lines.”
But that’s not the red flag. The real question isn’t whether Anthropic is being straight with us., it’s whether anyone, Anthropic included is actually equipped or positioned to evaluate something like this.
And the honest answer, the one the document almost arrives at before retreating into careful corporate language, is: probably not yet.
The full system card is available from Anthropic’s website herewith an archive.org backup I captured here. If you’re keen on exploring - I’d recommend at minimum reading the alignment assessment (Section 4) and the model welfare assessment (Section 5) also, regardless of where you stand on AI safety. The cyber section (Section 3) is fascinating if you’re into security. The rest is important context but you can skim.